
O projeto Tidy Tuesday
O projeto Tidy Tuesday é um projeto semanal de análise de dados no R. A iniciativa dá ênfase em compreender como organizar, processar e visualizar dados utilizando os pacotes ggplot2, tidyr, dplyr e outras ferramentas do universo tidyverse.
A iniciativa
1. toda terça-feira será publicado um banco de dados novo
e diferente sobre os mais variados assuntos. O banco de dados é disponibilizado
através deste [repósitório]() no Github.
2. Cientistas, entusiastas e estudantes do mundo todo utilizam o mesmo banco de
dados para realizar análises e responder perguntas diferentes.
3. Os gráficos e o código das análises são compartilhados com a hashtag
#TidyTuesday nas redes sociais.
4. Todo mundo aprende um pouco sobre R, gráficos e sobre o tema da semana.
Gostaram? Então mãos a obra.
Semana 38: Cetacean Dataset
O banco de dados desta semana é sobre Cetáceos e esta disponível no GIthub.
Pacotes necessários
library(tidyverse) # ggplot2, dplyr, etc
library(RCurl) # para baixar os dados diretamente do Github
Banco de dados
Descrição:
Uma coleção de dados sobre baleias e golfinhos que passram algum tempo em cativeiro nos USA entre 1938 e 2017.
Baixando os dados
Utilizamos o pacote RCurl para baixar os dados do repositório.
### Load data----
url <- "https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2018/2018-12-18/allCetaceanData.csv"
d <- read_csv(getURL(url))
glimpse(d)
## Observations: 2,194
## Variables: 22
## $ X1 <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 1...
## $ species <chr> "Bottlenose", "Bottlenose", "Bottlenose", "Bottlenos...
## $ id <chr> "NOA0004614, AZA 428, MLF-428", "NOA0004386, AZA 138...
## $ name <chr> "Dazzle", "Tursi", "Starbuck", "Sandy", "Sandy", "Na...
## $ sex <chr> "F", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M...
## $ accuracy <chr> "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a...
## $ birthYear <chr> "1989", "1973", "1978", "1979", "1979", "1980", "198...
## $ acquisition <chr> "Born", "Born", "Born", "Born", "Born", "Born", "Bor...
## $ originDate <date> 1989-04-07, 1973-11-26, 1978-05-13, 1979-02-03, 197...
## $ originLocation <chr> "Marineland Florida", "Dolphin Research Center", "Se...
## $ mother <chr> "Betty III", "Little Bit", "Cindy (T.t. gilli)", "Gi...
## $ father <chr> "Davy II", "Mr. Gipper", "Sambo", NA, NA, "Jethro (T...
## $ transfers <chr> NA, NA, "SeaWorld San Diego to SeaWorld Aurora (??-?...
## $ currently <chr> "Marineland Florida", "Dolphin Research Center", "Se...
## $ region <chr> "US", "US", "US", "US", "US", "US", "US", "US", "US"...
## $ status <chr> "Alive", "Alive", "Alive", "Alive", "Alive", "Alive"...
## $ statusDate <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,...
## $ COD <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, ...
## $ notes <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "Sunny was o...
## $ transferDate <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,...
## $ transfer <chr> "US", "US", "US", "US", "US", "US", "US", "US", "US"...
## $ entryDate <date> 1989-04-07, 1973-11-26, 1978-05-13, 1979-02-03, 197...
O banco de dados possui 2194 observações (linhas) e 22 variáveis (colunas).
Análises e perguntas
Olhando este banco de dados eu me fiz as seguintes perguntas
Quais são as espécies mais frequentes (top 10)?
nsp <-
d %>%
count(species, sort = T) %>%
top_n(n = 10)
nsp
## # A tibble: 10 x 2
## species n
## <chr> <int>
## 1 Bottlenose 1668
## 2 Killer Whale; Orca 79
## 3 Beluga 68
## 4 White-sided, Pacific 56
## 5 Pacific White-Sided 41
## 6 Commerson's 37
## 7 Spinner 36
## 8 Beluga Whale 28
## 9 Short-Finned Pilot Whale 25
## 10 Pilot, Short-fin 22
### Gráfico
ggplot(nsp, aes(x = reorder(species, n), y = n)) +
geom_col(fill = "lightblue", color = "white") +
scale_y_log10() +
theme_minimal(base_size = 14) +
labs(x = "Espécie",
y = "Número de indivíduos em cativeiro") +
coord_flip()
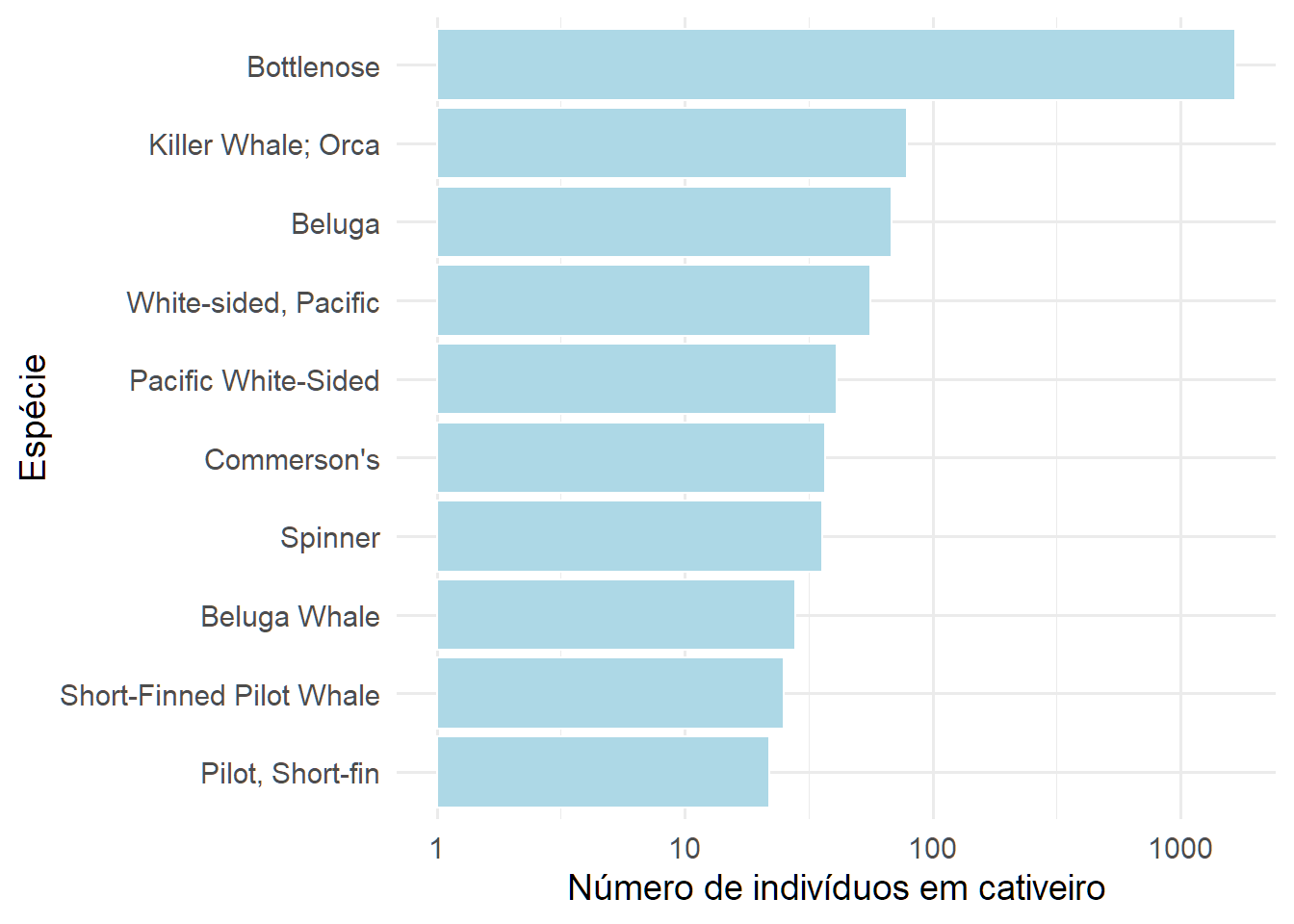
Como podemos ver o grupo Tursiops (Bottlenose) é o que tem o maior número de indivíduos em cativeiro (mais de 1000 indivíduos). Este grupo é um gênero de golvinhos cosmopolitas, com pelo menos três espécies:

Para incluir também uma espécies de baleia, irei filtrar o banco de dados para
as especies: "Bottlenose" e "Killer Whale; Orca".

Faremos todas as análises de dados a partir destas duas espécies.
dd <- d %>%
filter(species %in% c("Bottlenose", "Killer Whale; Orca" ))
Qual a a distribuição do sexo dos indivíduos entre essas duas espécies?
dc <- dd %>%
group_by(species, sex) %>%
count()
### Gráfico
ggplot(dc, aes(x = species, y = n, fill = sex)) +
geom_col(position = "fill", alpha = .75) +
geom_hline(yintercept = 0.5, lty = "dotted") +
theme_minimal(base_size = 14) +
scale_fill_manual(values = c("#66c2a5",
"#fc8d62",
gray(.8)),
name = "Sexo",
labels = c("Macho", "Fêmea", "Sem informação")) +
labs(y = "Proporção de indivíduos",
x = "") +
coord_flip()
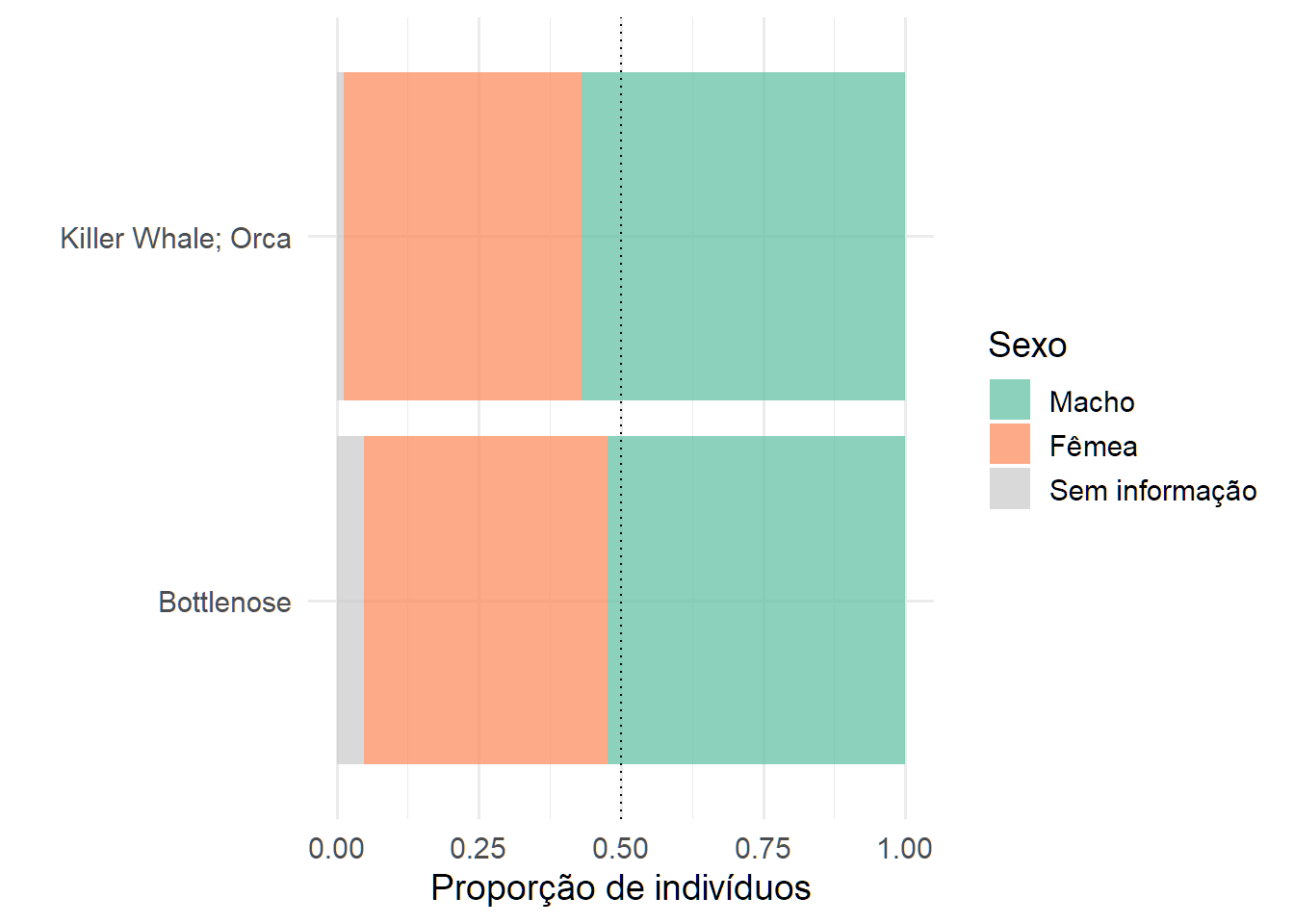
Dicas e sugestões?
Tem alguma crítica? Sugestão? Deixe um comentário ;)
Até a próxima aventura =)

